Suite…
Quelques réflexions complémentaires
Tout d’abord un très bel article pour ceux qui sont intéressés par le skewness et kurtosis
http://bdesgraupes.pagesperso-orange.fr/UPX/L1/Stats_seance_05_doc.pdf
Et ses différents mode de calculs. Perso je préfère le coefficient de Fisher qui a le mérite de donner le sens de la courbe de distribution
Quoi qu’il en soit après avoir analyser ces différents facteurs d’analyse, globalement le skewness est assez proche du SQN, ce qui est normal du fait d’un mode de calcul assez proche, et je pense donc que cela fait doublon. Je reste dubitatif sur son intérêt qui n’est simplement que d’évaluer sa forme par rapport à une loi normale, mais bon.
Le kurtosis a peut être un intérêt supérieur, à voir
Après lecture d’un article sur quantopia dont j’ai oublié la référence, j’ai bien aimé la conclusion.
En gros les backtests servent UNIQUEMENT à éliminer les mauvais algorithmes mais pas à sélectionner les bons candidats pour du réel
Autrement dit si l’algo ne passe même pas les backtests il y a fort à parier qu’en réel ce ne sera pas bon (quoique…) mais qu’un très bon backtest en l’état actuel ne prédit EN AUCUN CAS une corrélation avec les résultats en réel
A suivre, je pense que je vais coder un algo avec un très bon kurtosis et voir ce que cela donne
A +
mais qu’un très bon backtest en l’état actuel ne prédit EN AUCUN CAS une corrélation avec les résultats en réel
Dans l’IS ou dans l’OOS ? Dans les données hors échantillon, c’est logique même si testé robuste. Par contre dans les données IS, il faut introduire les frais et des simulations de slippage et de spread variables si nécessaires et si toutefois l’algo respecte bien les données techniques imposées par le courtier et le marché, et si tout cela est bien pris en compte, on peut quand même s’approcher d’un vrai forward test.
Backtest IS Nicolas
Sincèrement je rejoins les auteurs américains pour remuer tout ce qui est remuable depuis bien bien longtemps
Un backtest IS va te donner les meilleurs résultats possibles, (c’est bon pour l’ego), en gros la meilleur courbe de régression linéaire de résultats possible et ce d’autant que l’on superoptimise (Plus on superoptimise plus les résultats OOS risquent d’être changeants)
En gros le backtest “simple” élimine les mauvais et on “espère” qu’un bon/très bon backtest IS, sur sa lancée, intérêt du kurtosis, va donner les même résultats OOS, mais dans les fait bah aucune certitude et extrêmement variable.
Un WF donnera peut être une peilleure prévision, mais cela reste à confirmer
Une idée à tester, il faut encore que je la code c’est d’appliquer un Skewnsess/kurtosis non pas sur les gains mais sur le drawndown car un max drawndown est trop succinct.
A voir je code ça et je reviens vers vous
Bonjour,
Commençons par le début.
Pour avoir un bon back test,
-il faudrait qu’il ne manque aucune bougie
– pas erreur de calcul
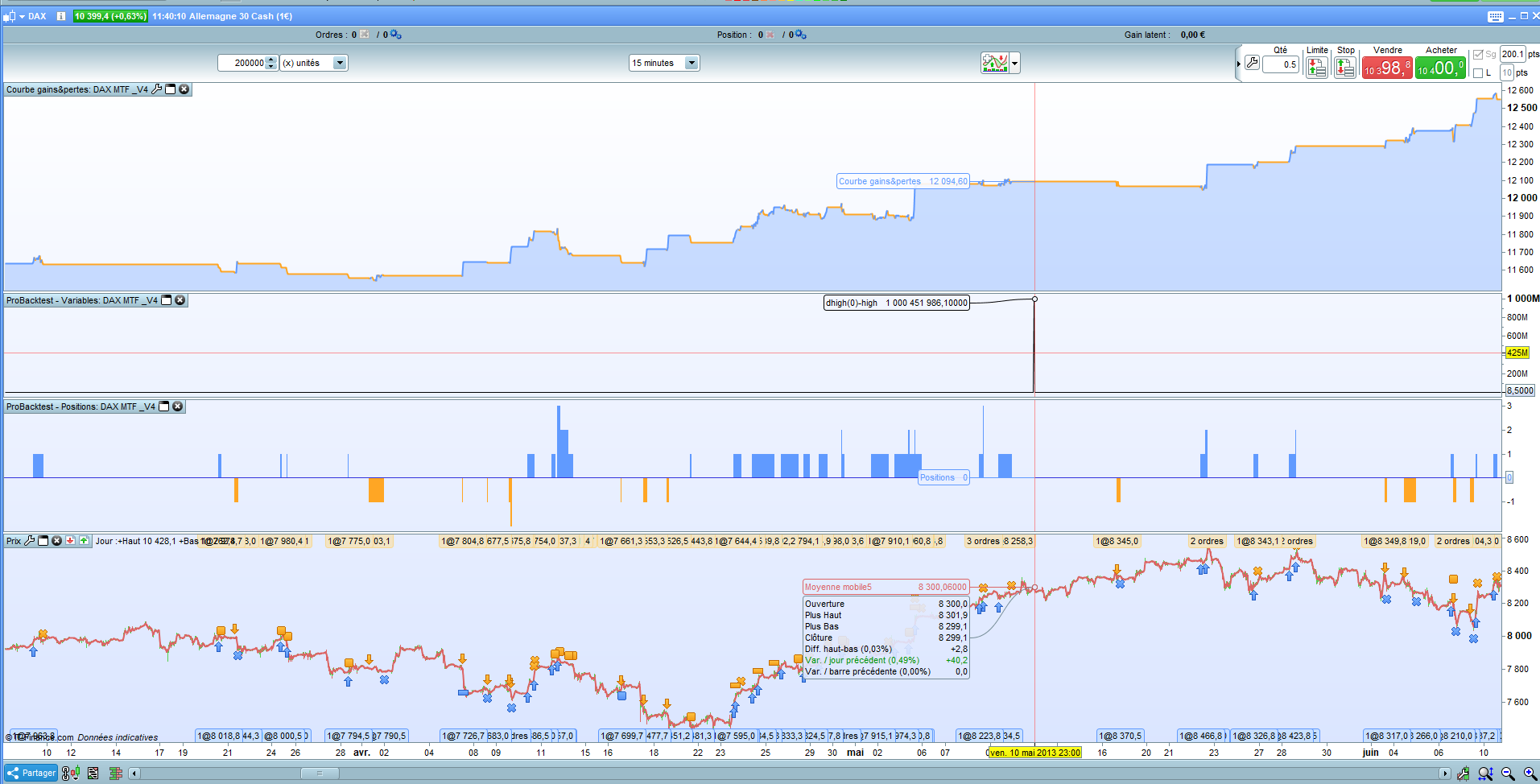
Regarde la pièce jointe comment est ce possible obtenir ce nombre si élevé ?
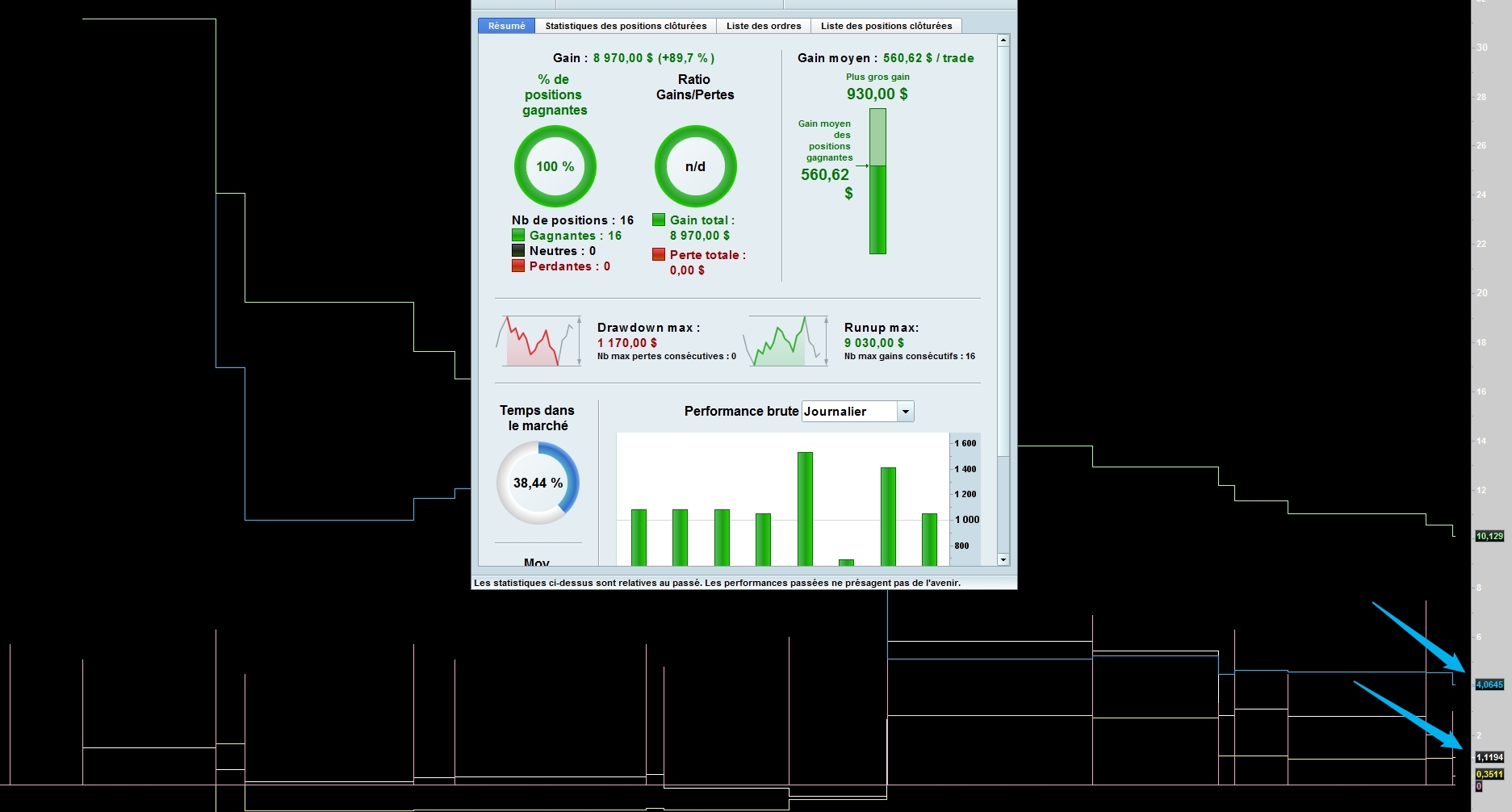
Illustration du rôle et de l’importance potentielle du kurtosis (“régularité”) sur un même algo
On voit que pour un même algo, avec 100 % de trades positifs (on s’en fiche), et un SQN assez proche 3-4 on est du simple au double sur le kurtosis de Fisher ! Idem pour le skewness de Fisher
Cela peut donc tout à fait avoir un impact (A voir en tout cas si ce n’est pas un élement sous jacent qui “confirmerait” la corrélation selon l’étude quantopia)
Et pour la petite histoire devinez lequel est ressorti en premier dans le backtest 😉 Et oui le deuxième avec les moins bons résultats (En attendant que l’on puisse faire des backtest sur des variables que l’on aurait codé)
A suivre
j’ai graphé dhigh(0)-high et le nombre est 1 000 486 986
CA me semble impossible
Oui curieux graph dhigh(0) et high pour voir lequel picole, teste avec un autre indice etc..et si reproductible contacte le support PRT
Un backtest IS va te donner les meilleurs résultats possibles,
Non, si tu ne fait aucune optimisation et cela affirme ce que tu disais plus tôt: les backtests servent UNIQUEMENT à éliminer les mauvais algorithmes (donc sans opti on sait que ça ne fonctionne pas ou peu) mais pas à sélectionner les bons candidats pour du réel (oui car même correct en pseudo forward testing hors échantillon avec l’analyse WF, on ne sait jamais de quoi sera fait demain).
Mais comme je le répète souvent, le fait de vouloir un backtest qui te donne un résultat positif à la fin de la période que tu analyses, c’est déjà une optimisation, et donc un biais introduit consciemment dans la machine.
L’analyse que tu portes sur la distribution de tes résultats, elle se fait à la volée durant le backtest, où tu introduits un filtre après les premiers résultats obtenus sans celui-ci ?
Je pense que l’on est d’accord
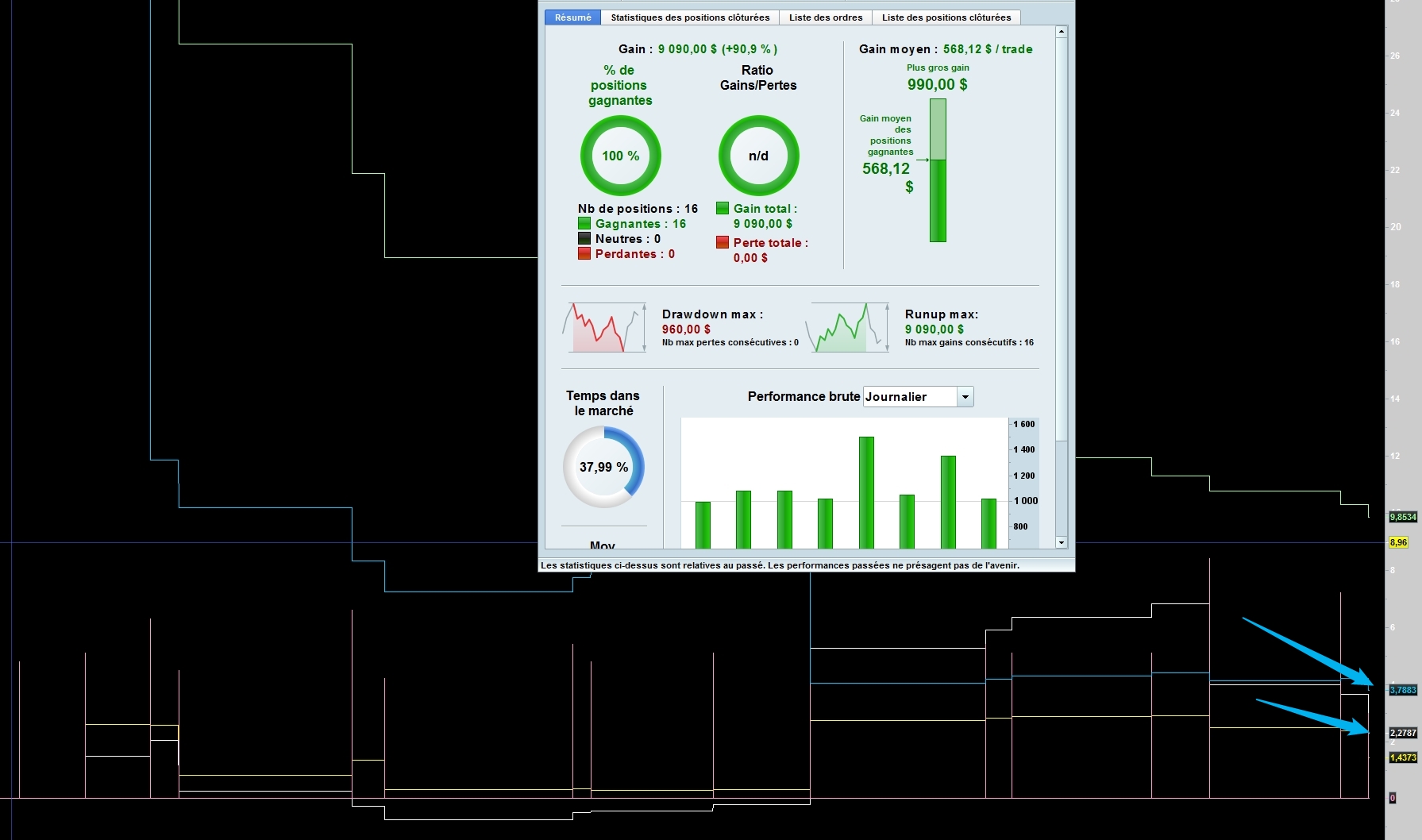
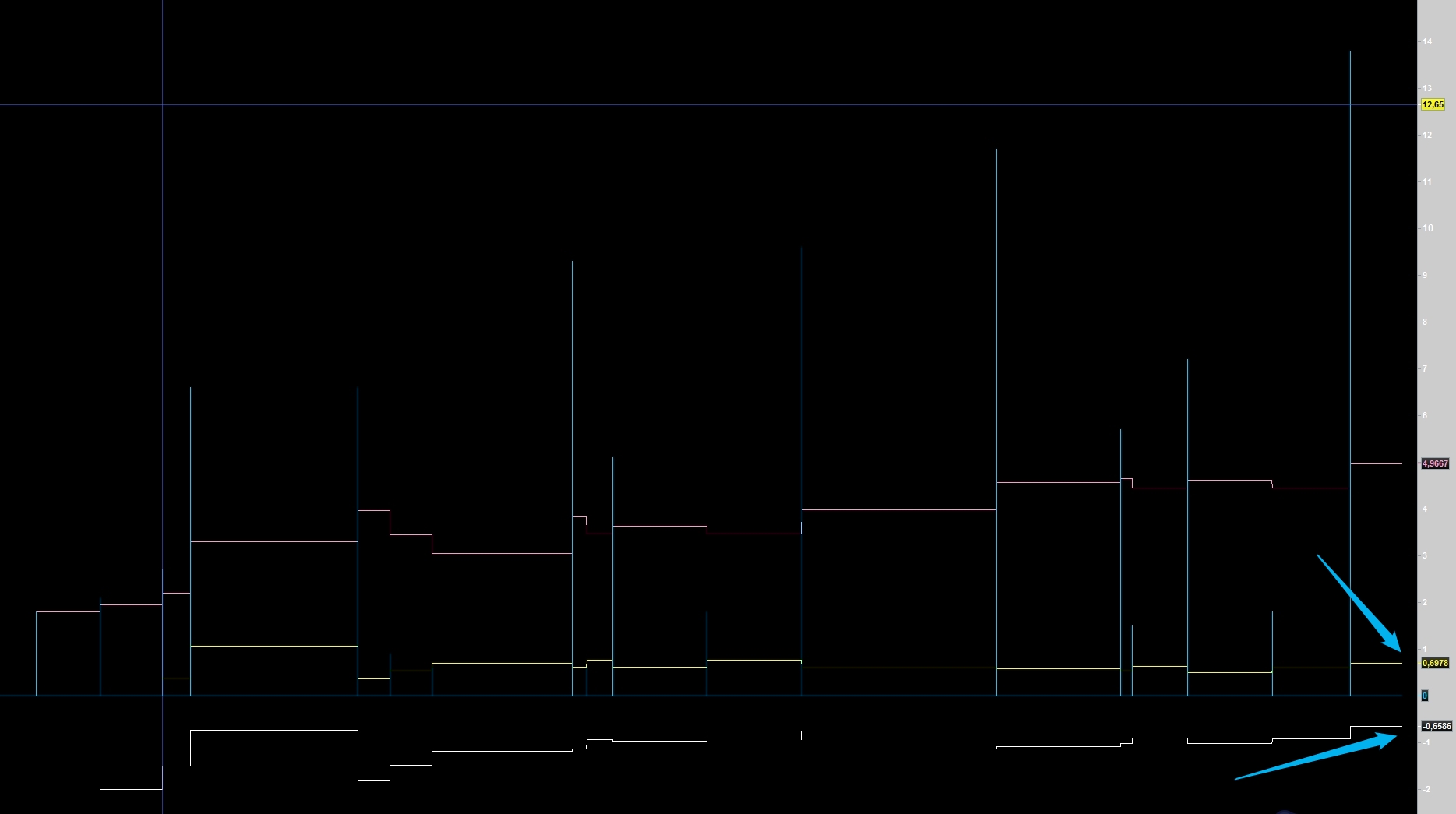
A la volée durant le backtest Nicolas comme sur l’image ci-dessous, pas de filtre à la fin car trop chronophage
Par ex ci sur l’image kurtosis de 8.9 ce qui est très bon et en accord avec la courbe ascendante=tendance=régularité de cet algo
Ce que j’ai du mal à interpréter c’est le skewness parce que là on est à -2.7 ce qui laisserait penser que la courbe des gains est décalée vers la gauche mais les gains sont très réguliers. Curieux
je me trompe il n’y a pas de SL
je me trompe il n’y a pas de SL
Si, toujours, ça évite les déconvenues
Je pense que l’on est d’accord
A la volée durant le backtest Nicolas comme sur l’image ci-dessous, pas de filtre à la fin car trop chronophage
Par ex ci sur l’image kurtosis de 8.9 ce qui est très bon et en accord avec la courbe ascendante=tendance=régularité de cet algo
Ce que j’ai du mal à interpréter c’est le skewness parce que là on est à -2.7 ce qui laisserait penser que la courbe des gains est décalée vers la gauche mais les gains sont très réguliers. Curieux
Intéressant.. tu te bases sur ce genre de chose pour les calculer ?
a=std[periodo](close)
b=average[periodo](close)
n=periodo
s=a*a*a
//computation skeweness
Skewprimo=summation[periodo](close*close*close)
Skewsecondo=-3*b*summation[periodo](close*close)
Skewterzo=3*b*b*summation[periodo](close)
Skewquarto=-b*b*b*n
modskew=(skewprimo+skewsecondo+skewterzo+skewquarto)/(n*s)
//computation kurtosis
kurtprimo=summation[periodo](close*close*close*close)
kurtsecondo=-4*b*summation[periodo](close*close*close)
kurtterzo=6*b*b*summation[periodo](close*close)
kurtquarto=-4*b*b*b*summation[periodo](close)
kurtquinto=+b*b*b*b*n
modkurt=((kurtprimo+kurtsecondo+kurtterzo+kurtquarto+kurtquinto)/(n*s*a))-3
Je suis parti de là mais je crains qu’il y est des erreurs dans le code comme précisé à l’auteur c’est pourquoi je suis reparti de zéro
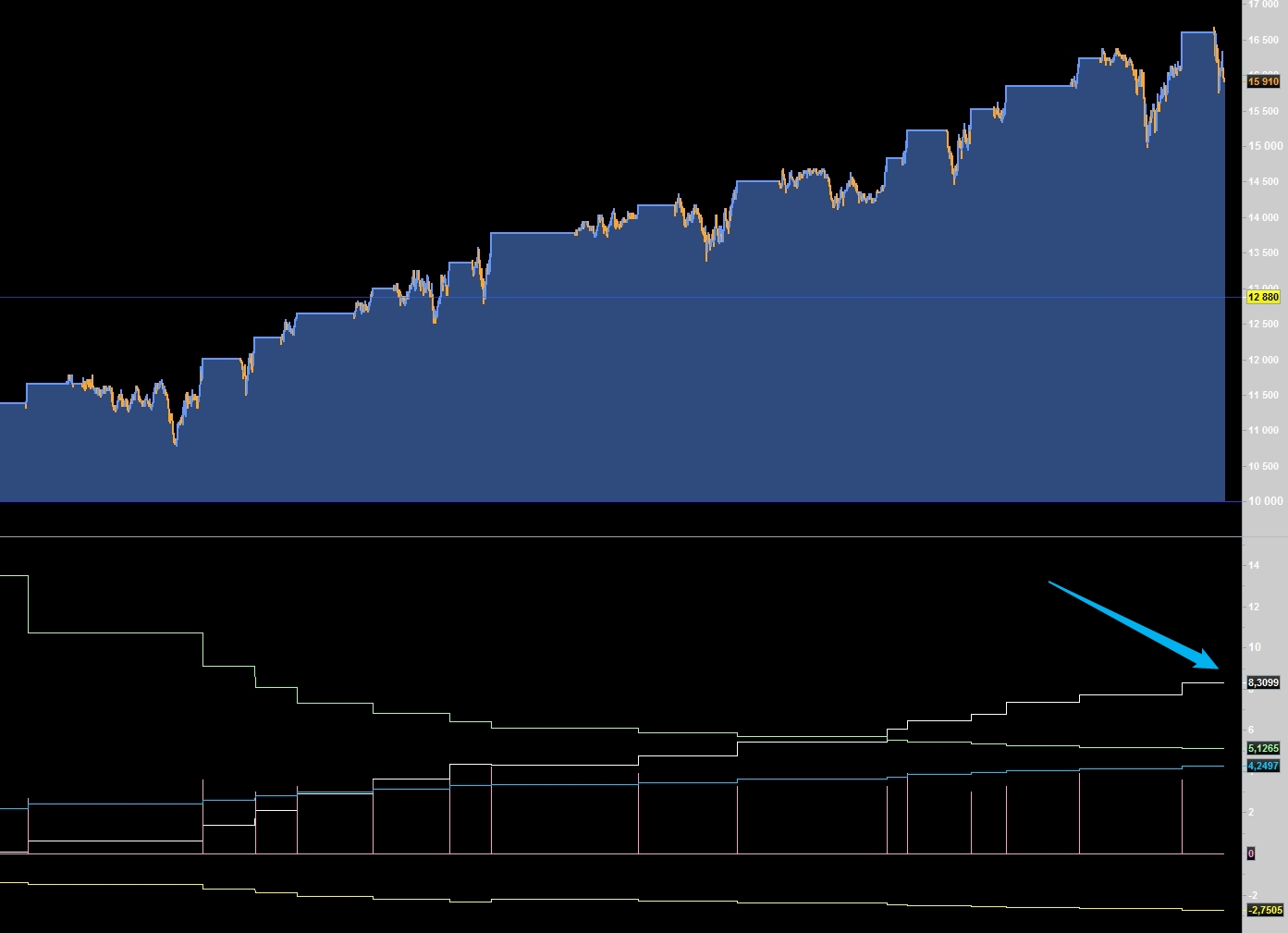
Bon désolé le codage du kurtosis et skewness sur le drawdown par trade a été un peu trapu
Bilan, en pièce jointe c’est assez étonnant, autant sur les algo on a un très bon kurtosis et un skewness très variable autant sur le drawdown le skewness et le kurtosis sont relativement constants avec un skewness et un kurtosis proche de 0 = proche d’une loi normale
Curieux mais à confirmer sur d’autres algo. ce qui laisserait sous entendre que le drawndown par trade varie sur tout le range entre 0 et le max drawndown avec 95 % des valeurs dans moy+2ecarts type
A suivre