Fr7
Fr7Participant
Master
Hola Nicolas,
¿Puede ayudarme a sustituir en el código original el “DPO” por el DPO con datos del pasado?
for i = 1 to 3
// Blue (Long term)
if i = 1 then
k = blue
det = DPO[k*2](close)
if det=det[1] and det[1]=det[2] and det[2]<>det[3] then
flag = 1
endif
n = (k*2)-4
p = (n/2)-1
d100 = DPO[n](close)
moy100 = close-d100
co = (moy100-moy100[1]+(close[p])/n)*n
h100 = dpo[n](high)
moyh = high-h100
hi = (moyh-moyh[1]+(high[p])/n)*n
l100 = dpo[n](low)
moyl = low-l100
lo = (moyl-moyl[1]+(low[p])/n)*n
if flag=1 and flag[1]=0 then
somx = 0
somy = 0
somxx = 0
somxy = 0
for i=1 to k
somx = somx+i
next
for i=0 to k-1
somy=somy+co[i]
next
for i=1 to k
somxx=somxx+(i*i)
next
for i=0 to k-1
somxy=somxy+(co[i]*(k-i))
next
a = (k*somxy-somx*somy)/(k*somxx-somx*somx)
b = (somy-a*somx)/k
for i=0 to k-1
ecah = hi[i]-a*(k-i)-b
maxh = max(maxh,ecah)
ecal = a*(k-i)+b-lo[i]
maxl = max(maxl,ecal)
next
endif
if flag=0 then
reg = undefined
else
j = j + 1
reg = a * j + b
endif
raffBlue = max(maxh,maxl)
rafflBlue = reg-raffBlue
raffhBlue = reg+raffBlue
riffBlue = min(maxh,maxl)
riffhBlue = reg+riffBlue
rifflBlue = reg-riffBlue
// (optional) - let's take an average of the riff and raff
BlueResistance = (raffhBlue + riffhBlue) / 2
BlueSupport = (rafflBlue + rifflBlue) / 2
Fr7Participant
Master
He estado intentándolo pero no lo consigo…………
avg = average[p](customclose)
avgH = average[p](HIGH)
avgL = average[p](LOW)
r = round(p/2) +1
b = customclose - avg[r]
C=HIGH-AVGH[R]
D=LOW-AVGL[R]
myDPO = b
MYDPOH=C
MYDPOL=D
P=14
K=48
for i = 1 to 3
// Blue (Long term)
if i = 1 then
k = blue
det = MYDPO[k*2]
if det=det[1] and det[1]=det[2] and det[2]<>det[3] then
flag = 1
endif
n = (k*2)-4
p = (n/2)-1
d100 = MYDPO[n]
moy100 = close-d100
co = (moy100-moy100[1]+(close[p])/n)*n
h100 = MYdpoH[n]
moyh = high-h100
hi = (moyh-moyh[1]+(high[p])/n)*n
l100 = MYdpoL[n]
moyl = low-l100
lo = (moyl-moyl[1]+(low[p])/n)*n
if flag=1 and flag[1]=0 then
somx = 0
somy = 0
somxx = 0
somxy = 0
for i=1 to k
somx = somx+i
next
for i=0 to k-1
somy=somy+co[i]
next
for i=1 to k
somxx=somxx+(i*i)
next
for i=0 to k-1
somxy=somxy+(co[i]*(k-i))
next
a = (k*somxy-somx*somy)/(k*somxx-somx*somx)
b = (somy-a*somx)/k
for i=0 to k-1
ecah = hi[i]-a*(k-i)-b
maxh = max(maxh,ecah)
ecal = a*(k-i)+b-lo[i]
maxl = max(maxl,ecal)
next
endif
if flag=0 then
reg = undefined
else
j = j + 1
reg = a * j + b
endif
raffBlue = max(maxh,maxl)
rafflBlue = reg-raffBlue
raffhBlue = reg+raffBlue
riffBlue = min(maxh,maxl)
riffhBlue = reg+riffBlue
rifflBlue = reg-riffBlue
// (optional) - let's take an average of the riff and raff
BlueResistance = (raffhBlue + riffhBlue) / 2
BlueSupport = (rafflBlue + rifflBlue) / 2
.¿Dónde está el error?
Fr7Participant
Master
¿Me puede ayudar alguien ?
 AVT
AVTParticipant
Senior
¿Por qué quiere usted pintar este en el pasado?
Sería más fácil si usted sólo muestra sus modificaciones comparado al original, ejemplo:
// P=14 // original
// K=48 // original
P=14
K=48
El código original es demasiado largo sólo para encontrar un error en la modificación.
Fr7Participant
Master
Hola Avt,es sólo la parte donde sale “dpo”:
for i = 1 to 3
// Blue (Long term)
if i = 1 then
k = blue
det = DPO[k*2](close)
if det=det[1] and det[1]=det[2] and det[2]<>det[3] then
flag = 1
endif
n = (k*2)-4
p = (n/2)-1
d100 = DPO[n](close)
moy100 = close-d100
co = (moy100-moy100[1]+(close[p])/n)*n
h100 = dpo[n](high)
moyh = high-h100
hi = (moyh-moyh[1]+(high[p])/n)*n
l100 = dpo[n](low)
Fr7Participant
Master
Quiero sustituirlo para poder realizar sistema automático,porque con “dpo” no es posible sistema automático.
Fr7Participant
Master
Esto es lo que yo he modificado pero no funciona, a ver si alguien me puede ayudar …
avg = average[p](customclose)
avgH = average[p](HIGH)
avgL = average[p](LOW)
r = round(p/2) +1
b = customclose - avg[r]
C=HIGH-AVGH[R]
D=LOW-AVGL[R]
myDPO = b
MYDPOH=C
MYDPOL=D
P=14
K=48
for i = 1 to 3
// Blue (Long term)
if i = 1 then
k = blue
det = MYDPO[k*2]
if det=det[1] and det[1]=det[2] and det[2]<>det[3] then
flag = 1
endif
n = (k*2)-4
p = (n/2)-1
d100 = MYDPO[n]
moy100 = close-d100
co = (moy100-moy100[1]+(close[p])/n)*n
h100 = MYdpoH[n]
moyh = high-h100
hi = (moyh-moyh[1]+(high[p])/n)*n
l100 = MYdpoL[n]
moyl = low-l100
lo = (moyl-moyl[1]+(low[p])/n)*n
DPO o se ajusta a la fórmula de datos:
// **** DPO of past moving average and not future ones :
p = 14
avg = average[p](customclose)
r = round(p/2) +1
b = customclose - avg[r]
myDPO = b
RETURN myDPO as "Detrented Price Oscillator of past datas", 0 coloured(10,10,255) as "0"
Fr7Participant
Master
// **** DPO of past moving average and not future ones :
p = 14
avg = average[p](customclose)
r = round(p/2) +1
b = customclose - avg[r]
myDPO = b
//////////////////////////////////
for i = 1 to 1
// Blue (Long term)
if i = 1 then
k = blue
det = myDPO[k*2]
if det=det[1] and det[1]=det[2] and det[2]<>det[3] then
flag = 1
endif
n = (k*2)-4
p = (n/2)-1
d100 = myDPO[n]
moy100 = close-d100
co = (moy100-moy100[1]+(close[p])/n)*n
h100 = myDPO[n](high)
moyh = high-h100
hi = (moyh-moyh[1]+(high[p])/n)*n
l100 = myDPO[n](low)
NO FUNCIONA SUSTITUÉNDOLO POR MYDPO
Lo que está tratando de hacer aquí NUNCA FUNCIONARÁ. Si el autor original del canal Raff ha utilizado el indicador DPO es porque usa datos futuros, por lo que matemáticamente hablando es posible conocer el futuro y saber cómo dibujar correctamente el canal. Pero no funciona en absoluto con DPO como el indicador para dibujar el canal, por lo que usar los datos pasados DPO no será útil en este caso.
FR7 he conseguido un proorder con DPO.. me ha costado la santa vida.. pero lo he conseguido aunque si te digo que no da el mismo resultado.. pero si lo ves contacta y hablamos
@osupero
DPO non è compatibile con ProOrder perché questo indicatore utilizza dati futuri! Come ti ho già detto, ti preghiamo di considerare che non sarai in grado di usarlo in tempo reale! Puoi provare la versione di DPO con dati reali che ho postato qui: https://www.prorealcode.com/topic/sustiutir-dpo/#post-49581
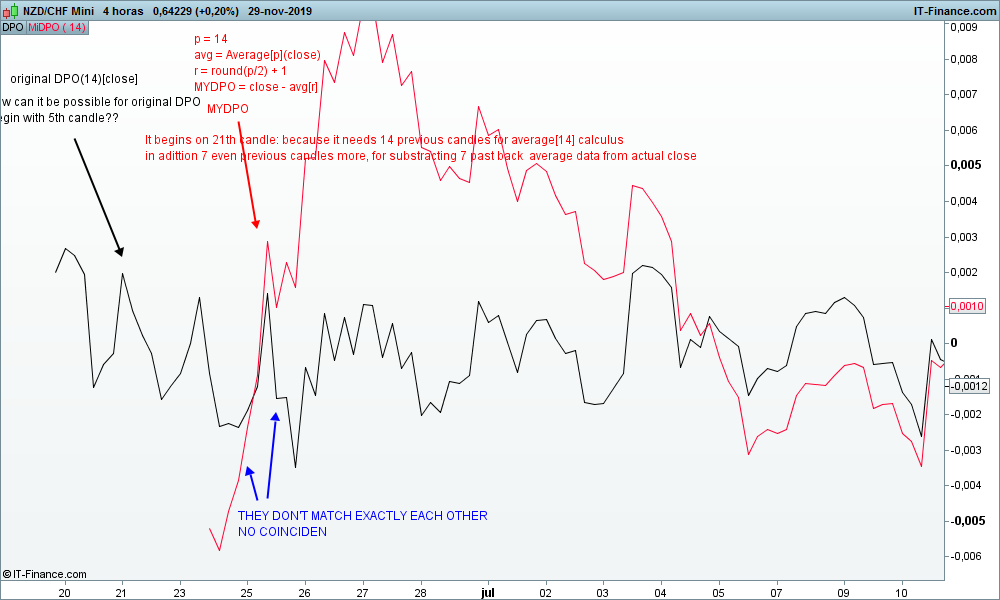
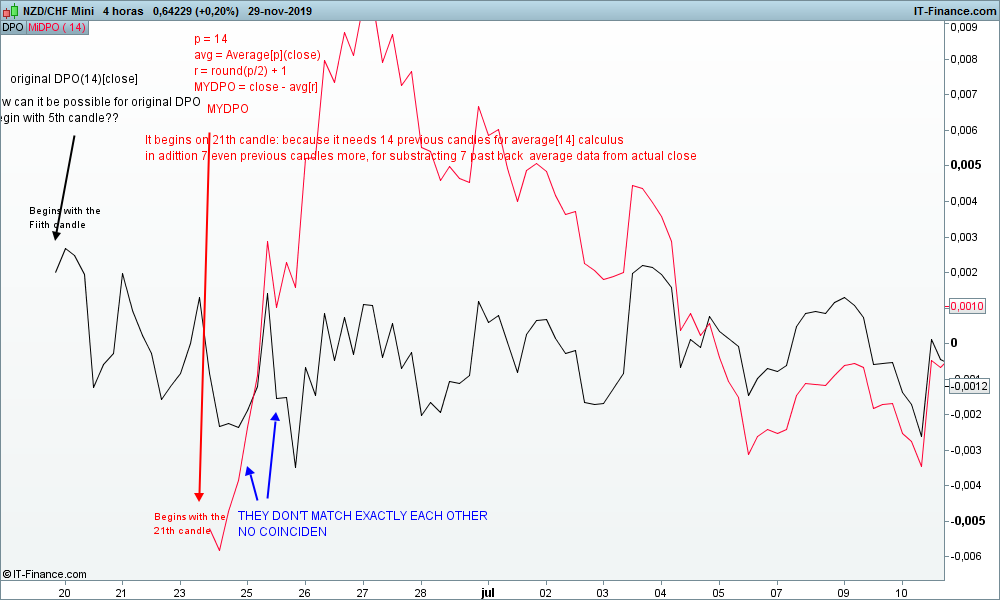
Sin embargo Nicolás, la versión casera MYDPO hecha con tu receta no parece coincidir exactamente con la original DPO, tal y como se puede apreciar en la foto que acompaña. En concreto me pregunto ¿cómo la DPO original puede comenzar en la 5ª vela del gráfico?, siendo que la versión casera comienza en la vela 21 ( necesita 14 velas previas para calcular la Average[14](close) + aún 7 velas anteriores previas más, para restarle al cierre actual la Average[14](close[7]))
Cómo conseguir pues que coincidan exáctamente??? Gracias por tus esfuerzos.
<hr />
Nicolás´ homemade MYDPO seems not to be exactly match with the original DPO…. How can original DPO begin with 5th candle in the chart? Meanwhile homemade MYDPO needs to begin with 21th candle in chart? (14 previous candles for Average[14](close) purposes in adittion 7 even previous candles more, for substracting past data Average from actual close)
How could we do in order to get they exactly match each other please?? Any ideas welcome. Thank you in advance
A ver, yo encuentro que la MYDPO casera calculada con tu receta (que es la misma de Nicolás) no parece coincidir exáctamente con la DPO original, tal y como se puede ver en la foto que adjunto. Nada más al comienzo del gráfico la DPO original empieza a dibujarse a partir de la quinta vela, mientras que la MYDPO casera empieza a pintarse a partir de la 21ª vela. Me gustaía averiguar como conseguir coincidieran exactamente las dos.